

Building Modern Serverless APIs with CDK, Python, and GraphQL (Part 4)
Designing Event Driven Applications

R
I love creating and writing about the creation of software.
Search for a command to run...
Designing Event Driven Applications
I love creating and writing about the creation of software.
No comments yet. Be the first to comment.
Learn how to build scalable and reliable APIs with AWS AppSync! Our blog series provides step-by-step tutorials and best practices for beginners and pros.
Designing Event Driven Applications
How to Generate Files on Demand and Deliver Download URLs Using GraphQL Subscriptions

Using Pre-Signed URLs for Scalable, Secure File Handling in GraphQL APIs

Find the path to achieving AppSync excellence, by following those simple best practices

Over the past years, event-driven architecture has become more and more popular. With the arrival of services such as EventBridge and its integration with many other AWS services, building such applications has become easier than ever. Last year, AWS...

What's new in V1.0.0?
Welcome to the fourth part of this article series.
In Part 1, we gave a brief overview of the concept of event-driven architectures, coupling, and defined all AWS services needed to build the API.
In Part 2, we created a new CDK project, and added CDK resources for our GraphQL API, alongside a GraphQL Schema, an SQS queue, a DynamoDB table, and an SNS Topic.
In Part 3, we created resources and lambda functions for the step functions workflow.
Let's continue from where we left off in part 3.
From the GraphQL schema, the endpoint is under Query
orders: [ Order ]!
We'll be using a Lambda function resolver to resolve this endpoint. Other alternatives are VTL resolvers or the newly added javascript resolvers. For now, Javascript resolvers are only compatible with applications built with Javascript (nodeJs or Typescript).
From my experience building GraphQL APIs, it's always better to use VTL resolvers for querying purposes. They are quicker, have zero cold starts, and are ideal in situations where there is less data manipulation.
But for this tutorial, we'll be querying the order data using a Lambda resolver. Sorry 😅
The first step towards creating our resolver is to first create a handler with the code to query DynamoDB.
Create a python package called get_orders within the lambda-fns folder. Create a python file called get_order.py within the get_orders folder.
Type in the following code to query all orders from the table.
def process_response(data):
print(data)
data["id"] = data["id"]["S"]
data["quantity"] = data["quantity"]["N"]
data["name"] = data["name"]["S"]
data["restaurantId"] = data["restaurantId"]["S"]
data["orderStatus"] = data["orderStatus"]["S"]
return data
def fetch_all_orders(dynamo_client, table_name):
results = []
last_evaluated_key = None
while True:
if last_evaluated_key:
response = ddb_client.scan(
TableName=table_name, ExclusiveStartKey=last_evaluated_key
)
else:
response = dynamo_client.scan(TableName=table_name)
last_evaluated_key = response.get("LastEvaluatedKey")
response = map(process_response, response["Items"])
response = list(response)
results.extend(response)
if not last_evaluated_key:
break
print(f"fetch_all_orders returned {results}")
return results
def handler(event, context):
items = fetch_all_orders(ddb_client, TABLE_NAME)
return items
We are using a scan and LastEvaluatedKey to paginate through the data in the database. This is not efficient and performant. As a matter of fact, don't do this. This is for tutorial purposes only.
In a real application, you'll want to make use of the query function and Global Secondary indexes (GSI) for better performance and scalability.
The next step is to define the lambda resources, the data source, and the lambda resolver.
I created a separate folder for files like this. So within the root folder, create a python package called lambda_resources. Within that folder, create a python file called get_all_orders_lambda_resource.py.
Type in the following code.
def get_all_orders_lambda_resource(stack, api, schema, db_role, lambda_execution_role):
with open("lambda_fns/get_orders/get_orders.py", "r") as file:
get_all_order_lambda_function = file.read()
get_all_order_function = lambda_.CfnFunction(
stack,
"gets",
code=lambda_.CfnFunction.CodeProperty(zip_file=get_all_order_lambda_function),
role=db_role.role_arn,
# the properties below are optional
architectures=["x86_64"],
description="lambda-ds",
environment=lambda_.CfnFunction.EnvironmentProperty(
variables={"ORDER_TABLE": "ORDER"}
),
function_name="get-orders-function",
handler="index.handler",
package_type="Zip",
runtime="python3.9",
timeout=123,
tracing_config=lambda_.CfnFunction.TracingConfigProperty(mode="Active"),
)
We've seen similar code like this above. So we'll go ahead and create a new AppSync data source and then attach our lambda to it.
Within the same file, type in this code
lambda_get_all_order_config_property = appsync.CfnDataSource.LambdaConfigProperty(
lambda_function_arn=get_all_order_function.attr_arn
)
lambda_get_all_order_data_source = appsync.CfnDataSource(
scope=stack,
id="lambda-getAll-order-ds",
api_id=api.attr_api_id,
name="lambda_getAll_order_ds",
type="AWS_LAMBDA",
lambda_config=lambda_get_all_order_config_property,
service_role_arn=lambda_execution_role.role_arn,
)
Using the LambdaConfigProperty we specify the lambda functions ARN for AppSync's Datasource. Then in the CfnDataSource method, we specify the AppSync's API id, the type of Datasource (AWS_LAMBDA) the name of the Datasource, the lambda configuration, and the AWS IAM role ARN for the Datasource.
The next step is defining the resolver.
# Resolvers
## list orders resolver
get_all_orders_resolver = appsync.CfnResolver(
stack,
"list-orders",
api_id=api.attr_api_id,
field_name="orders",
type_name="Query",
data_source_name=lambda_get_all_order_data_source.name,
)
In the above code, using the CfnResolver method from AppSync, we add in the AppSync API id, the field_name and type_name as specified in the GraphQL schema, and also the name of the Datasource we created above.
Lastly, since the resolver depends on the GraphQL schema and Datasource, we need to specify that also, using the add_dependency method.
get_all_orders_resolver.add_dependency(schema)
get_all_orders_resolver.add_dependency(lambda_get_all_order_data_source)
We are just adding a CloudFormation dependency between both resources.
The final step is to call this function get_all_orders_lambda_resource(stack, api, schema, db_role, lambda_execution_role) from the stack file and pass in all required parameters.
I'll assume you've already added your account and region as environment variables to your app file in app.py.
Run
cdk synth in order to synthesize your app.
Then run
cdk bootstrap to provision CloudFormation resources to the environment (region and account) we added to the app above.
Finally, we have to deploy the app. Remember that we need to pass in an email address as a parameter during deployment so that it can be used to subscribe to SNS for emails.
Run this command to deploy your app
cdk deploy --parameter subscriptionEmail=YOUR_EMAIL_ADDRESS
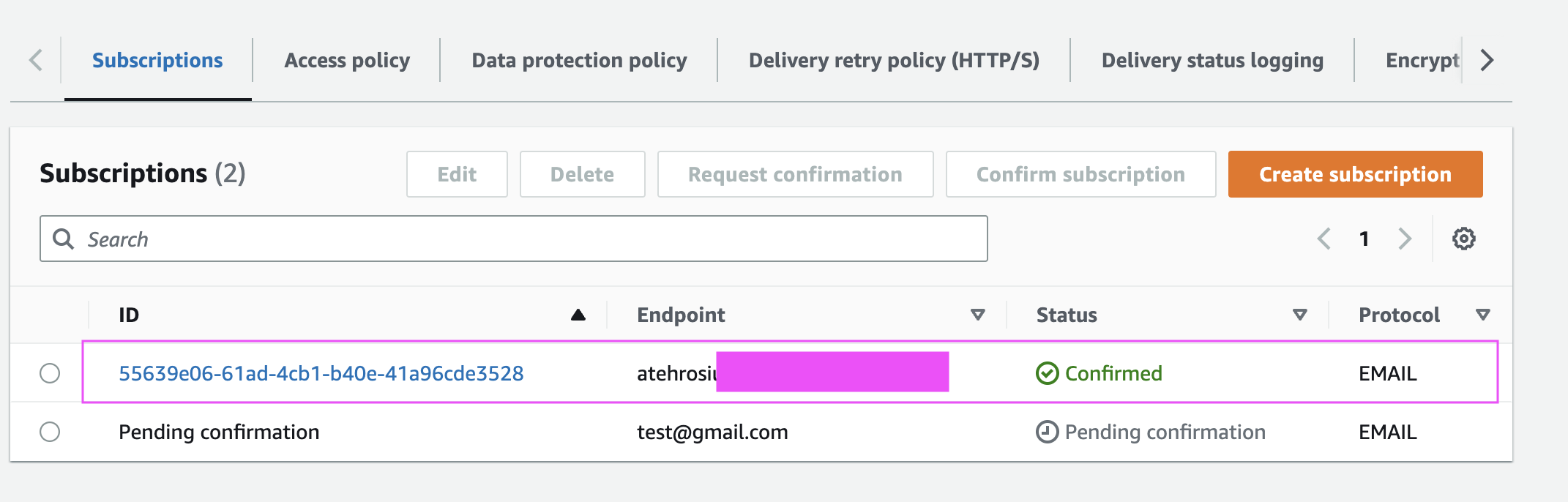
If the app is successfully deployed, you should receive a subscription email from amazon. Check your spam folder.
Clicking on the link in the email subscribes that email to the SNS topic we created above sns topic.
If you log into the AWS console and navigate to SNS, under your topic, you should see all subscribed emails.
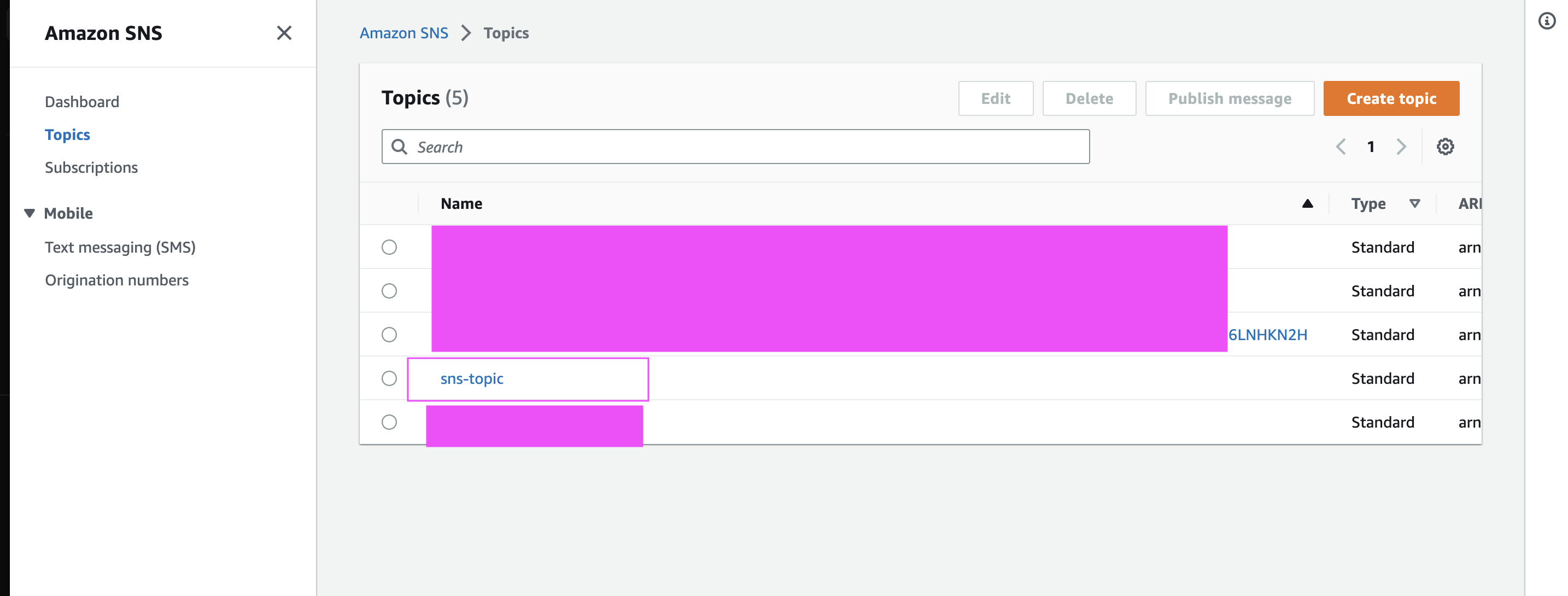
Subscribers
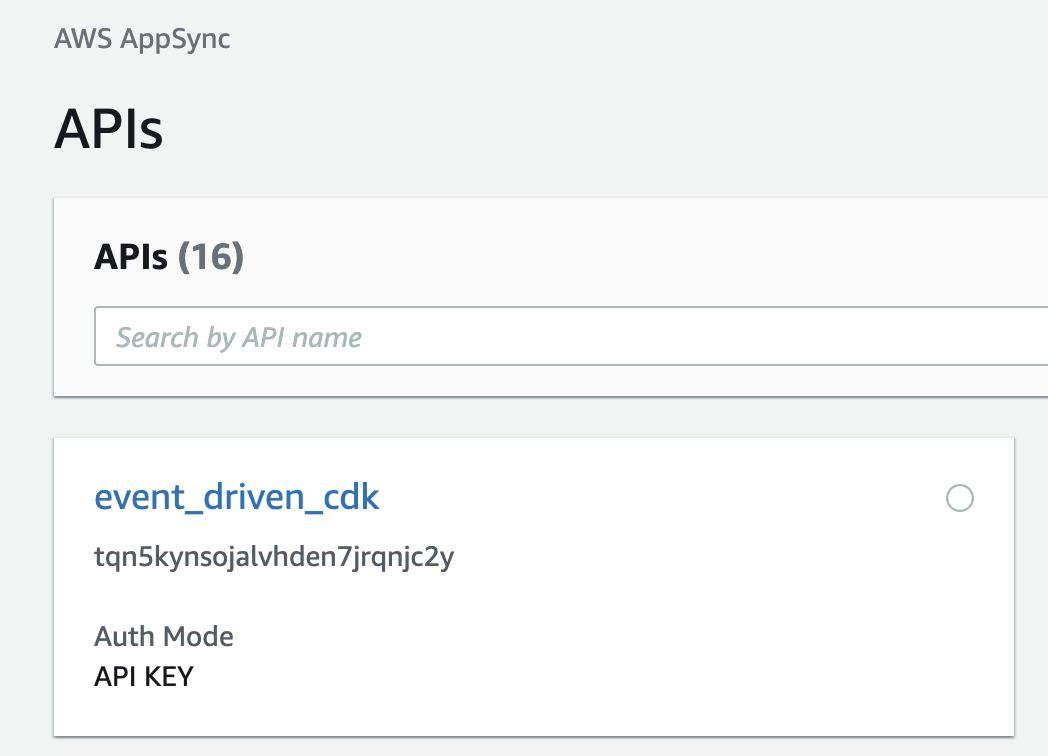
Navigate to AppSync from the AWS console. Select and open your project from the list of APIs.
In this article, we added an endpoint to get all orders in the database. We saw how to build the lambda function, create a Datasource and a resolver, then crowned it all up by deploying the app to the cloud, while passing in an email address as a parameter.
So what's left now is testing, and we'll be seeing that in the final episode of this series. Stay tuned. If you loved this piece, please like or comment. Happy Coding ✌🏾